MCP Servers Do Not Force Tools Into Context
It's common for developers new to MCP to complain that the protocol bloats their context window and tanks agent performance. It’s a real problem, but they're wrong about what's causing it.
MCP gives you a clean, standardized interface for connecting AI agents to external tools and services. But it doesn’t tell you how to manage those tool definitions once you have them. That's the agent harness's job, and many harnesses get it wrong. The result gets blamed on MCP.
How Context Bloat Happens
Imagine you're building a general purpose agent for a product manager. You connect your first MCP server, the GitHub MCP, and call list_tools. You get back a clean list of tool definitions and pass them into context so the agent can determine which one to use. Everything works.
A few weeks go by, and you've added Notion, Salesforce, and an internal data warehouse MCP. You do the same thing you did before with GitHub: call list_tools on each server, concatenate the results, pass them all into context. You now have over 100 tools loaded on every single turn!
Most tool definitions look like this, which runs about 130 tokens:
{
"name": "get_weather",
"title": "Weather Information Provider",
"description": "Get current weather information for a location",
"inputSchema": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City name or zip code"
}
},
"required": ["location"]
}
}
At 130 tokens per tool, 100 tools cost 13,000 tokens before the user has typed a single word. And most of those tokens are wasted: on any given task, the model only needs a handful of tools, not all 100. This creates three compounding problems:
- Cost. In many AI-powered applications, LLM costs are the biggest line item, and without a better pattern, tool definitions would be a meaningful fraction of your inference bill.
- Latency. Time-to-first-token scales with prompt token count (and by rough corollary, context length). A bloated tool list adds measurable delay to every response, on every request, regardless of whether those tools were ever needed.
- Focus. Research shows LLM task accuracy degrades as context length grows, with relevant information increasingly ignored when buried among irrelevant content. More tools in context means the model is less likely to correctly select and use the ones it actually needs.
MCP-heavy agents do suffer real performance problems in practice. But the cause isn't MCP. As we'll see in a moment, this is easily solvable with a better harness pattern.
The Fix: Meta-Tools
When you load hundreds of tool definitions into a context window and ask a model to pick the right one, you're essentially performing search with one of the most expensive pieces of software ever built. However, searching over text is a practically solved problem, and we can do this with code. We do this by exposing just two meta-tools to the model.
The first is search_tool. When the model needs a capability, it calls search_tool with a natural language or keyword query. The harness searches across all available tool definitions using keyword matching or semantic search and returns only the top few most relevant schemas for the current task. This is where the token savings happen: instead of 100 definitions loaded blindly, the model gets back a small, targeted subset relevant to what it's actually trying to do.
The second is execute_tool. Once the model has identified the right tool from the search results, it calls execute_tool to run it. Together, search_tool and execute_tool form a complete abstraction layer over the entire tool inventory. The model never needs raw access to all tool definitions at once.
The tradeoff is one extra round trip: the model calls search_tool, receives a small set of relevant definitions, then calls execute_tool to run the one it needs. But for almost any application complex enough to need dozens of MCP tools, better model performance is worth it. The applications that need 100+ tools are rarely the ones where a single extra step is a dealbreaker.
The architecture also scales cleanly. Whether you have four MCP servers or forty, the model's effective tool context stays small and task-relevant on every turn. None of this requires changes to the MCP servers themselves.
The Real Problem: Security
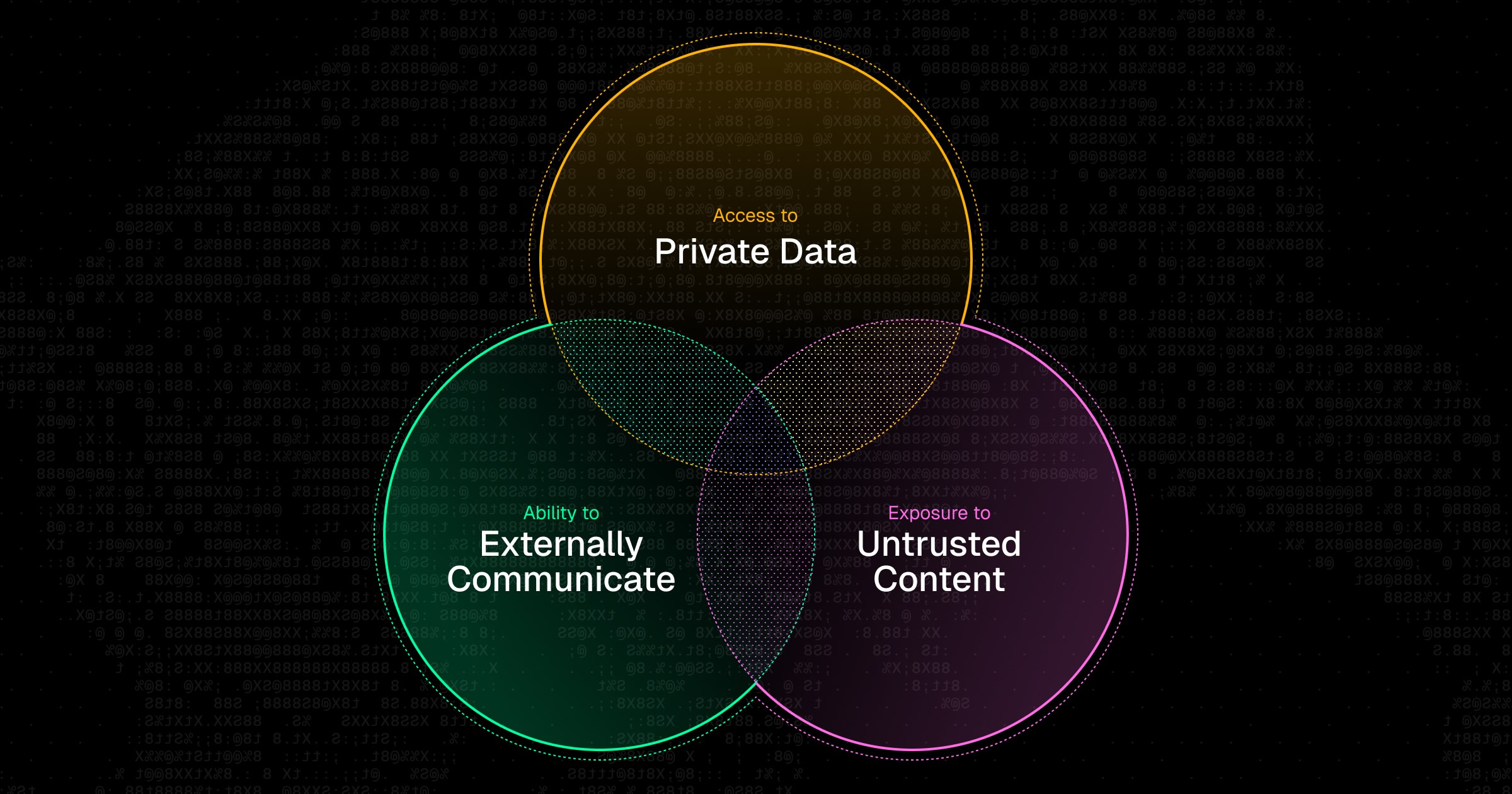
The meta-tool pattern solves context bloat in a way that makes adding new MCP servers essentially free. But scalability raises a harder question: if any agent can dynamically discover and invoke any tool across any connected MCP server, who's making sure those tools are safe to call?
This is a real concern for MCP. There have already been high-profile attacks across multiple vectors: malicious instructions embedded in tool descriptions themselves, and prompt injections hidden in user-facing data like GitHub issues that hijack agents when tools return that content. As MCP usage grows, the attack surface grows with it.
Getting the performance architecture right is necessary but not sufficient. You also need governance: control over which MCP servers agents can connect to, enforcement of company-approved tool lists, and protection against tool definitions that carry injected instructions. That's what Runlayer does.



.jpg)